How to Scrape IMDb Top Box Office Movies Data using Python?
Our achievements in the field of business digital transformation.





Different Libraries for Data Scrapping
We all understand that in Python, you have various libraries for various objectives. We will use the given libraries:
BeautifulSoup: It is utilized for web scraping objectives for pulling data out from XML and HTML files. It makes a parse tree using page source codes, which can be utilized to scrape data in a categorized and clearer manner.
Requests: It allows you to send HTTP/1.1 requests with Python. Using it, it is easy to add content including headers, multipart files, form data, as well as parameters through easy Python libraries. This also helps in accessing response data from Python in the similar way.
Pandas: It is a software library created for Python programming language to do data analysis and manipulation. Particularly, it provides data operations and structures to manipulate numerical tables as well as time series.
For scraping data using data extraction with Python, you have to follow some basic steps:
1: Finding the URL:
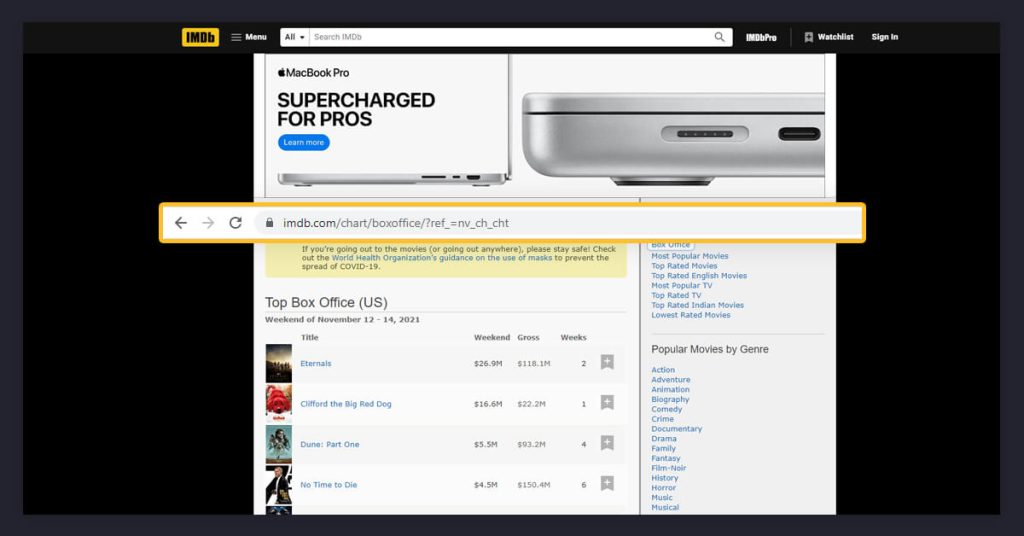
Here, we will extract IMDb website data to scrape the movie title, gross, weekly growth, as well as total weeks for the finest box office movies in the US. This URL for a page is https://www.imdb.com/chart/boxoffice/?ref_=nv_ch_cht
2: Reviewing the Page
Do right clicking on that element as well as click on the “Inspect” option.
3: Get the Required Data to Scrape
Here, we will going to scrape data including movies title, weekly growth, and name, gross overall, and total weeks taken for it that is in “div” tag correspondingly.
4: Writing the Code
For doing that, you can utilize Jupiter book or Google Colab. We are utilizing Google Colab here:
Import libraries:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Make empty arrays and we would utilize them in the future to store data of particular column.
TitleName=[]
Gross=[]
Weekend=[]
Week=[]
Just open the URL as well as scrape data from a website.
url = "https://www.imdb.com/chart/boxoffice/?ref_=nv_ch_cht"
r = requests.get(url).content
With the use of Find as well as Find All techniques in BeautifulSoup, we scrape data as well as store that in a variable.
soup = BeautifulSoup(r, "html.parser")
list = soup.find("tbody", {"class":""}).find_all("tr")
x = 1
for i in list:
title = i.find("td",{"class":"titleColumn"})
gross = i.find("span",{"class":"secondaryInfo"})
weekend = i.find("td",{"class":"ratingColumn"})
week=i.find("td",{"class":"weeksColumn"}
With append option, we store all the information in an Array, which we have made before.
TitleName.append(title.text)
Gross.append(gross.text)
Weekend.append(weekend.text)
Week.append(week.text)
5. Storing Data in the Sheet. We Store Data in the CSV Format
df=pd.DataFrame({'Movie Title':TitleName, 'Weekend':Weekend, 'Gross':Gross, 'Week':Week})
df.to_csv('DS-PR1-18IT012.csv', index=False, encoding='utf-8')
6. It’s Time to Run the Entire Code
All the information are saved as IMDbRating.csv within the path of a Python file.
For more information, contact 3i Data Scraping or ask for a free quote about IMDb Top Box Office Movies Data Scraping services.













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



