How to Scrape Alibaba.com Product Data Using Scrapy?
3i Data Scraping assists you to Scrape Alibaba.Com Product Data Scraping Services. You will get accurate data as per the clients’ requirements in different formats such as CSV, Excel, and JSON.
Our achievements in the field of business digital transformation.





Scrapy is the most common open-source data scraping framework. Created in Python, this has the majority of modules that you would require to proficiently scrape, process, as well as store information from the websites in almost all structured data formats. Scrapy is the best option for web data crawlers that extracts data from different kinds of pages.
In this tutorial blog, we will exhibit you how to extract product data from Alibaba.com which is the world’s top marketplace.
Requirements
Installing Python 3 with Pip
We will utilize Python 3 in this tutorial. For starting, you require a computer having Python 3 as well as PIP.
You can use the guides given below for installing Python 3 as well as pip:
For Linux, use
https://docs.python-guide.org/starting/install3/linux/
For Mac, use
Package Installation
pip3 install scrapy selectorlib
If you want more information on installation, you can find from this links – https://doc.scrapy.org/en/latest/index.html
How to Start a Scrapy Project?
Let’s start a scrapy project with the given command.
Best Practices to Ensure Legitimate Data Scraping
scrapy startproject scrapy_alibaba
The given command makes the Scrapy project using a Project Name like (scrapy_alibaba) as a folder name. This will have all the required files having the suitable structure as well as fundamental docstrings for every file, having the structure close to
scrapy_alibaba/ # Project root directory
scrapy.cfg # Contains the configuration information to deploy the spider
scrapy_alibaba/ # Project's python module
__init__.py
items.py # Describes the definition of each item that we’re scraping
middlewares.py # Project middlewares
pipelines.py # Project pipelines file
settings.py # Project settings file
spiders/ # All the spider code goes into this directory
__init__.py
Making a Spider
Scrapy is having an in-built command named genspider for generating the fundamental spider templates.
scrapy genspider <spidername> <website>
Now, it’s time to produce our spider
scrapy genspider alibaba_crawler alibaba.com
as well as it will make the spiders/scrapy_alibaba.py file with the primary template for crawling alibaba.com.
Its code will look like that:
# -*- coding: utf-8 -*-
import scrapy
class AlibabaCrawlerSpider(scrapy.Spider):
name = 'alibaba_crawler'
allowed_domains = ['alibaba.com']
start_urls = ['http://alibaba.com/']
def parse(self, response):
pass
The Alibaba Crawler class receives the basic class scrapy.spider as the Spider class understand how to use links as well as scrape data from the web pages however it doesn’t identify where to see or which data to scrape. We would add this data later.
Functions & Variables
- name is a spider’s name which was provided in a typical generation command.
- You can utilize this name for starting the spider from a command line.
- The listing of allowed_domains are domains, which a spider is permitted to crawl
- The start_urls is a URL that a spider would start scraping whenever it is entreated.
- parse() is a default callback technique of Scrapy that is asked for the requests without any explicitly given callback. The parse function becomes invoked after every start_url gets crawled. You may use this utility to parse the response, scrape the extracted data, as well as get newer URLs to trail by making newer requests (Request) through them.
Scrapy offers comprehensive data about crawling as you experience the logs and understand what’s going through in a spider.
- This spider is prepared with a bot name called “scrapy_alibaba” as well as prints all the packages utilized in a project having version numbers.
- Scrapy searches for the spider modules that are positioned in a /spiders directory. You can set the default values with variables like CONCURRENT_REQUESTS_PER_DOMAIN, CONCURRENT_REQUESTS, SPIDER_MODULES, and DOWNLOAD_TIMEOUT respectively.
- Burdened different components like extensions, middlewares, as well as pipelines that are required to cope with the requests
- Utilize the URLs given in the start_urls as well as rescued the HTML contents of a page. As we didn’t identify callbacks for start_urls then the reply is expected at parse() function. Also, we did not compose any lines for handling the response expected, so that the spider ended with the stats like pages extracted in a crawl, bandwidth utilized in the bytes, status code counts, total items scraped, etc.
Scraping Data from Alibaba
For this tutorial blog, we will scrape the following data fields from all search result pages of Alibaba:
- Product’s Name
- Pricing Range
- Product’s Image
- Product Links
- Minimum Order
- Seller’s Name
- Seller’s Response Rate
- Total Years as a Seller
You can go extra and extract pricing and product details depending on the orders and filters. Nowadays, we’ll make it simple as well as stick to the fields.
Whenever you search any keywords like “earphones”, you will observe that a result page is having a URL similar to https://bit.ly/3yIi31Z in which a parameter SearchText has the keywords you have searched for.
Making a Selectorlib Template to Use for Alibaba’s Search Results Pages
You would observe in this code that we have utilized a file named selectors.yml and this file makes the tutorial very easy to make as well as follow. The real magic behind the file is the tool named Selectorlib.
Selectorlib is the tool, which makes choosing, marking, as well as scraping data from web pages very easy. The Chrome Extension of Selectorlib helps you mark the data needed to scrape as well as creates XPaths or CSS Selectors required to scrape data and previews how data might look like.
Let’s go through how we have marked different fields in a code for different data we require from Alibaba’s Search Results pages using Selectorlib’s Chrome Extension
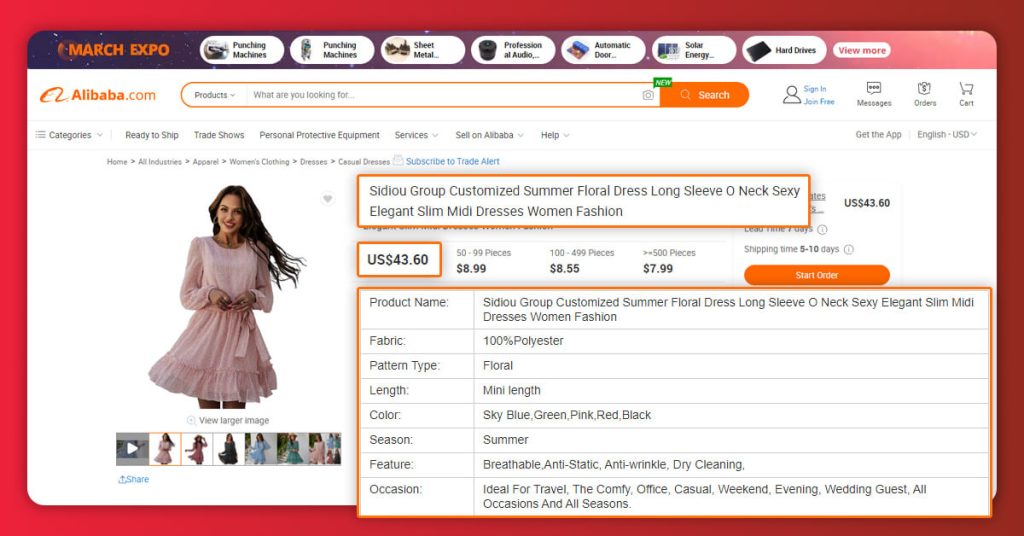
When you create the template, then click on the ‘Highlight’ option to highlight as well as preview all the selectors. Lastly, click on the ‘Export’ button and download the YAML file. Then save this file like search_results.yml in /resources folder.
Read Search Keywords from the File
We need to change the spider for reading keywords from the file from a folder named /resources given in a project directory as well as get products for different keyword inputs. We need to create a folder as well as make the CSV file within it named keywords.csv. The file will look like this in case, we require to search individually for headphones as well as earplugs.
- Keyword
- Headphones
- Earplugs
We need to utilize Python’s typical CSV module for reading the keyword file.
def parse(self, response):
"""Function to read keywords from keywords file"""
keywords = csv.DictReader(open(os.path.join(os.path.dirname(__file__),"../resources/keywords.csv")))
for keyword in keywords:
search_text = keyword["keyword"]
url = "https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText={0}&viewtype=G".format(search_text)
yield scrapy.Request(url, callback=self.parse_listing, meta={"search_text":search_text})
A Complete Scrapy Spider Code
Let’s run our data scraper using
scrapy crawl alibaba_crawler
DEBUG: Forbidden by robots.txt: <GET https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText=headphones&viewtype=G&page=1>
It is because the Alibaba website has not allowed crawling the URLs with trade/pattern. You may verify this through visiting a robots.txt page that is positioned at the location
https://www.alibaba.com/robots.txt
All the spiders made using Scrapy 1.1+ are already respecting robots.txt. You may disable it by setting variables like ROBOTSTXT_OBEY = False. At this time scrapy understands that it’s not required to check the robots.txt file. This will begin crawling different URLs given the start_urls listing.
Exporting Product Information in CSV or JSON with Scrapy
Scrapy offers built-in JSON or CSV formats.
scrapy crawl <spidername> -o output_filename.csv -t csv
scrapy crawl <spidername> -o output_filename.json -t json
To save the outputs in the CSV file:
scrapy crawl alibaba_crawler -o alibaba.csv -t csv
Using the JSON file:
scrapy crawl alibaba_crawler -o alibaba.csv -t json
It will make output files, which would be in the same folder as the script.
Just go through some sample information scraped from Alibaba in CSV.
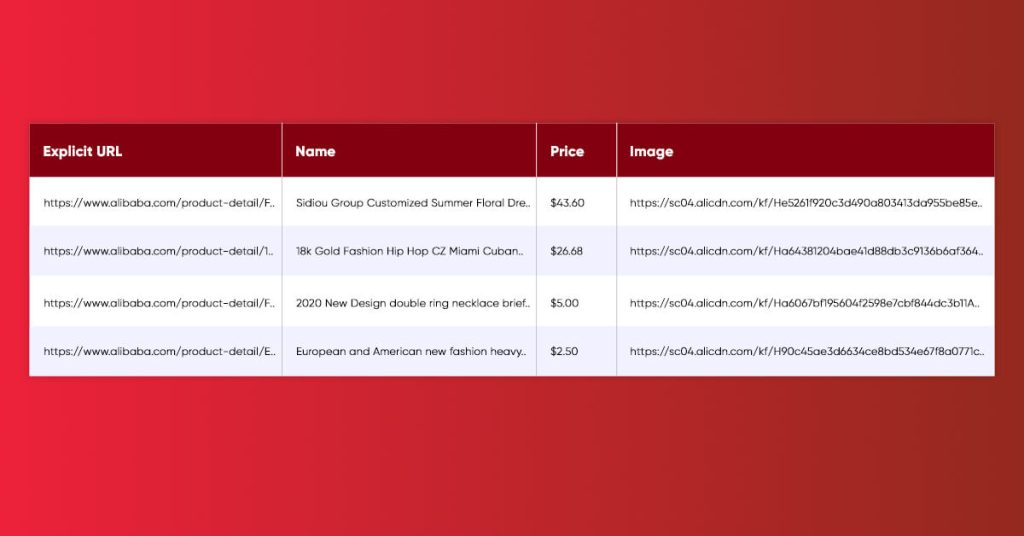
Some Limitations
The code needs to be capable enough to scrape the information of the majority of Alibaba product listings pages providing the structure continues to be the same or alike. If you find any errors associated with LXML whereas doing scraping, this might be because of:
- Anti-Scraping actions of Alibaba.com could have highlighted the crawler like a Bot.
- The website structure might get changed, making all selectors that we have void
Need to scrape or extract product data from Alibaba’s thousands of pages? If you want any professional assistance in scraping e-commerce products data, then contact us by filling the given form.













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



