How to Extract eBay Data for Original Comic Art Sales Information?
- December 22, 2021
Our achievements in the field of business digital transformation.





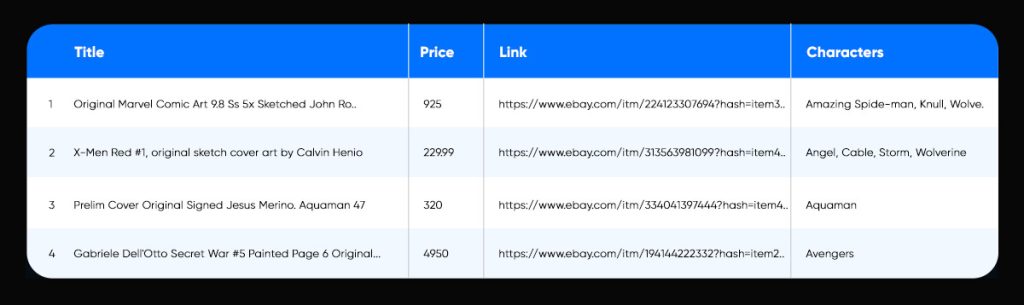
Data Fields to Be Scrapped
There is an example shown of the artwork drawn by hand in pencil by some artist and then another artist inks the drawing over them. Typically, 11 × 17-inch panels are used. The vitality of the drawing style, as well as the obvious skill, appeal to everyone.
Get two panels of original art for inside pages from Spiderman comics from the 1980s a few years ago, around 2010. You can pay perhaps $200 or $300 for them and made slightly more than twice that much when you sell them a year later.
Nonetheless, if you are interested in purchasing several pieces in the $200 level right now and wanted to get additional information before doing so.
Below written is the full code with the main output in two csv files.
The leading 800 listings of original comic art from Marvel comics in the form of internal pages, covers, or splash pages are ordered by price in the first csv file. The following fields are scraped from eBay in the csv:
- the title (which usually includes a 20-word description of the item, character, type of page)
- Price
- Link to the item’s full eBay sales page complete list of all figures in the artwork *just after first eBay search, the software cycles through the page numbers of new matches at the bottom. eBay flags the application as a bot and prevents it from scraping pages with numbers greater than four. This is fine because it only includes goods that are normally sold for less than $75, and nearly none of them are original comic art – they are largely copies or fan art.
The second file format is doing the same thing, but for things that have previously been sold, using the same search criteria. Because it requires Selenium.
If you execute Selenium more than two or three times in an hour, eBay will disable it and you will have to manually download the html of sold comic art.
Expected Result
You can check the result by executing the code once a day and look through the csv file for mostly lesser-known characters of $100-$300 US dollar range currently for the sale.
Tools that are used: Python, requests, BeautifulSoup, pandas
Here are the below steps that we will follow:
We will scrape the following product
- Using the “original comic art” as the search string
- only cover, interior pages, or splash pages
- only comic art from Marvel or DC
- comics above price of $50
- sorted by price + shipping and highest to lowest
- 200 results per page
We’ll find a comprehensive of available original comic art based on your search parameters. We’ll retrieve the title / brief explanation of the listing (as a single string), the page URL of the real listing, and the price for each listing.
We’ll get the main comic book character’s name in one field and the identities of all the characters in the image in a second field for each listing.
We’ll make a CSV file using an eBay product data scraper in the following format: a title, a price, a link, a character, and a character with several characters.
Installing all the Packages for the Project
!pip install requests --upgrade --quiet
!pip install bs4 --upgrade --quiet
!pip install pandas --upgrade --quiet
!pip install datetime --upgrade --quiet
!pip install selenium --upgrade --quiet
!pip install selenium_stealth --upgrade --quiet
Initially use the time package so that you can keep the record of the program’s progress and slowly use the date and time in the csv file name
import time
from datetime import date
from datetime import datetime
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
print("date and time:", today)
date and time: Jul-17-2021-15-14-55
Create a Function to Print the Data and Time
def update_datetime():
global now
global today
global date_time
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
print("date and time:", today)
Next Scrape the search URL
- To download the page, use the requests package.
- Employ Beautiful Soup (BS4) to look for appropriate HTML tags, parse them.
- Transform the artwork information to a Pandas dataframe.
<pre style="overflow: scroll; height: 560px;">import requests
from bs4 import BeautifulSoup
# original comic art, marvel or dc only, buy it now, over 50, interior splash or cover, sorted by price high to low
orig_comicart_marv_dc_50plus_200perpage='https://www.ebay.com/sch/i.html_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200'
orig_comicart_marv_dc_50plus_200perpage_sold='https://www.ebay.com/sch/i.html_fsrp=1&_from=R40&_sacat=0&LH_Sold=1&_mPrRngCbx=1&_udlo=50&_udhi&LH_BIN=1&_samilow&_samihi&_sadis=15&_stpos=10002&_sop=16&_dmd=1&_ipg=200&_fosrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&LH_Complete=1&_nkw=original%20comic%20art&_dcat=3984&rt=nc&Publisher=DC%2520Comics%7CMarvel%7CMarvel%2520Comics'
search_url = orig_comicart_marv_dc_50plus_200perpage
# there is a way to use headers in this function call to change the
# user agent so the site thinks the request is coming from
# different computers with different broswers but I could not get this working
# response = requests.get(url, headers=headers)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
</pre>
Unless there is an error, the response function will return 200. If this is the case, display the error code; otherwise, continue. doc is a BeautifulSoup (BS4) object that makes searching for HTML tags and navigating the Document Object Model a breeze (DOM)
Now Save the HTML Files
# first use the date and time in the file name
filename = 'comic_art_marvel_dc-' + today + '.html'
with open(filename, 'w') as f:
f.write(page_contents)
We can use h3 tags with the class’s-item title’ to acquire the listing’s title / description.
title_class = 's-item__title'
title_tags = doc.find_all('h3', {'class': title_class})
This locates all of the h3 tags in the BS4 documentation.
# make a list for all the titles title_list = []
loop through the tags and obtain only the contents of each one
for i in range(len(title_tags)):
# make sure there are contents first
if (title_tags[i].contents):
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
len(title_list)
202
print(title_list[:5])
['WHAT IF ASTONISHING X-MEN
#1 ORIGINAL J. SCOTT CAMPBELL COMIC COVER ART MARVEL',
'CHAMBER OF DARKNESS
#7 COVER ART (VERY FIRST BERNIE WRIGHTSON MARVEL COVER) 1970',
'MANEELY, JOE - WILD WESTERN
#46 GOLDEN AGE MARVEL COMICS COVER (LARGE ART) 1955',
'Superman vs Captain Marvel Double page splash art by Rich Buckler DC 1978 YOWZA!',
'SIMON BISLEY 1990 DOOM PATROL
#39 ORIGINAL COMIC COVER ART PAINTING DC COMICS']
since the price is in the same area of the html page as the title, let's use the findNext function. this time we will search for a 'span' element with class = 's-item__price'. also, when I tried to run separate functions to find the title, and then the price, there were sometimes duplicate title tags -- to the length of the lists would not match. I would get a title list with 202 items and a price list 200 items -- so these could not be joined in a dataframe.
Also, I imagine using findNext() and findPrevious() might make the whole search process a little faster.
We’ll use the findNext function because the price is in the same section of the html page as the title. We’ll look for a’span’ element with the class’s-item price’ this time. Furthermore, whenever I tried to execute separate functions to get the title and then the price, there were occasionally duplicate page titles – the lengths of the lists didn’t match. You would get a 202-item title list and a 200-item price list, which couldn’t be combined in a data frame.
In addition, You can use findNext() and findPrevious()that will speed up the entire search process.
price_class = 's-item__price'
price_list = []
for i in range(len(title_tags)):
# make sure there are contents first
if (title_tags[i].contents):
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if(i==1):
print(price)
This displays the price information during the last item listed on the first search page, out of a total of 200.
print(price.contents) ['$60.00']
Now you need to check if you are getting a string, and not a tag, and if so Strip the Dollar sign
from __future__ import division, unicode_literals
import codecs
from re import sub
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
print(price_string)
60.00
Converting the Price into a Floating-Point Decimal
price_num = float(price_string) print(price_num) 60.0
Place it All together in a Loop and Add all the Prices to a List
for i in range(len(title_tags)):
if (title_tags[i].contents):
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if price.contents:
price_string = price.contents[0]
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
price_num = float(price_string)
price_list.append(price_num)
print(len(price_list))
202
print(price_list[:5])
[50000.0, 45000.0, 18000.0, 16000.0, 14999.99]
now find an anchor tag with a reference and add the links to each distinct art listing
item_page_link = title_tags[i].findPrevious('a', href=True)
link_list = []
Clearing the Other Lists
title_list.clear()
price_list.clear()
for i in range(len(title_tags)):
if (title_tags[i].contents):
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if price.contents:
price_string = price.contents[0]
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
price_num = float(price_string)
price_list.append(price_num)
item_page_link = title_tags[i].findPrevious('a', href=True) # {'class': 's-item__link'})
if item_page_link.text:
href_text = item_page_link['href']
link_list.append(item_page_link['href'])
len(link_list)
202
print(link_list[:5])
Creating a DataFrame using the Dictionary
import pandas as pd title_price_link_df = pd.DataFrame(title_and_price_dict) len(title_price_link_df) 202 print(title_price_link_df[:5]) title ... link 0 WHAT IF ASTONISHING X-MEN #1 ORIGINAL J. SCOTT... ... https://www.ebay.com/itm/123753951902?hash=ite... 1 CHAMBER OF DARKNESS #7 COVER ART (VERY FIRST B... ... https://www.ebay.com/itm/312520261257?hash=ite... 2 MANEELY, JOE - WILD WESTERN #46 GOLDEN AGE MAR... ... https://www.ebay.com/itm/312525381131?hash=ite... 3 Superman vs Captain Marvel Double page splash ... ... https://www.ebay.com/itm/233849382971?hash=ite... 4 SIMON BISLEY 1990 DOOM PATROL #39 ORIGINAL COM... ... https://www.ebay.com/itm/153609370179?hash=ite... [5 rows x 3 columns]
We’re simply interested in the top six pages of results produced by our search address for now. We would potentially obtain 1200 listings ordered by price if the URL returned 200 listings per page. Unfortunately, eBay stops processing requests after the fourth page, resulting in 800 listings. Given the current traffic on eBay, this should be enough to get all products over $75. The listings below this amount are almost entirely made up of fan art rather than actual comic art.
So, the quick and simple method is to check for the pages in the lower left corner and click on each one to receive the connections to that page.
links_with_pgn_text = []
for a in doc.find_all('a', href=True):
if a.text:
href_text = a['href']
if (href_text.find('pgn=') != -1):
links_with_pgn_text.append(a['href'])
len(links_with_pgn_text)
7
print(links_with_pgn_text[:3])
Converting this into Function
def build_pagelink_list(url):
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
for a in doc.find_all('a', href=True):
if a.text:
href_text = a['href']
if (href_text.find('pgn=') != -1):
links_with_pgn_text.append(a['href'])
#below gets run if there is only 1 page of listings
if (len(links_with_pgn_text) < 1):
links_with_pgn_text.append(url)
links_with_pgn_text.clear()
build_pagelink_list(orig_comicart_marv_dc_50plus_200perpage)
len(links_with_pgn_text)
7
print(links_with_pgn_text)
Extracting the Old Items
Now we’ll scrape the internet for auctioned listings and prices. The long-term aim is to be able to detect products listed for sale and comparing their pricing to those of recently sold items to determine whether current listings are reasonably priced or underpriced and worth considering purchasing.
This second link only returns results for things that have already been sold, according to eBay. However, because this search yields fewer than 200 results, we’ll have to manually download the file for this notebook. This procedure, however, is automated using Selenium, and the code for it can be found below.
orig_comicart_marv_dc_50plus_200perpage_sold='https://www.ebay.com/sch/i.html_fsrp=1&_from=R40&_sacat=0&LH_Sold=1&_mPrRngCbx=1&_udlo=50&_udhi&LH_BIN=1&_samilow&_samihi&_sadis=15&_stpos=10002&_sop=16&_dmd=1&_ipg=200&_fosrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&LH_Complete=1&_nkw=original%20
Select File->Save Page as: webpage HTML only from Chrome if you need to save the page manually.
“sold listings.html” is the name of the file.
!apt update
!apt install chromium-chromedriver --quiet
from selenium import webdriver
from selenium_stealth import stealth
Hit:1 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease Ign:2 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease Hit:3 http://security.ubuntu.com/ubuntu bionic-security InRelease Ign:4 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease Hit:5 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release Hit:6 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease Hit:7 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release Hit:8 http://archive.ubuntu.com/ubuntu bionic InRelease Hit:9 http://archive.ubuntu.com/ubuntu bionic-updates InRelease Hit:10 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease Hit:11 http://archive.ubuntu.com/ubuntu bionic-backports InRelease Hit:12 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease Hit:14 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease Reading package lists... Done Building dependency tree Reading state information... Done 41 packages can be upgraded. Run 'apt list --upgradable' to see them. Reading package lists... Building dependency tree... Reading state information... chromium-chromedriver is already the newest version (91.0.4472.101-0ubuntu0.18.04.1). 0 upgraded, 0 newly installed, 0 to remove and 41 not upgraded.
def selenium_run(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
# open it, go to a website, and get results
driver = webdriver.Chrome('chromedriver',options=options)
# uncomment below and change paths if running locally (and comment the line above)
#PATH = '/Users/jmartin/Downloads/chromedriver'
#driver = webdriver.Chrome(options=options, executable_path=r"/Users/jmartin/Downloads/chromedriver")
stealth(
driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.53 Safari/537.36',
languages = "en",
vendor = "Google Inc.",
platform = "Win32",
webgl_vendor = "Intel Inc.",
renderer = "Intel Iris OpenGL Engine",
fix_hairline = False,
run_on_insecure_origins = False
)
driver.delete_all_cookies()
driver.get(url)
update_datetime()
#html_file_name = "sold_page_source-" + today + ".html"
html_file_name = "sold_listings.html"
with open(html_file_name, "w") as f:
f.write(driver.page_source)
return html_file_name
fname = selenium_run(orig_comicart_marv_dc_50plus_200perpage_sold)
date and time: Jul-17-2021-15-17-25
print(fname)
sold_listings.html
with open(fname) as fp:
doc = BeautifulSoup(fp, 'html.parser')
def selenium_run(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
# open it, go to a website, and get results
driver = webdriver.Chrome('chromedriver',options=options)
# uncomment below and change paths if running locally (and comment the line above)
#PATH = '/Users/jmartin/Downloads/chromedriver'
#driver = webdriver.Chrome(options=options, executable_path=r"/Users/jmartin/Downloads/chromedriver")
stealth(
driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.53 Safari/537.36',
languages = "en",
vendor = "Google Inc.",
platform = "Win32",
webgl_vendor = "Intel Inc.",
renderer = "Intel Iris OpenGL Engine",
fix_hairline = False,
run_on_insecure_origins = False
)
driver.delete_all_cookies()
driver.get(url)
update_datetime()
#html_file_name = "sold_page_source-" + today + ".html"
html_file_name = "sold_listings.html"
with open(html_file_name, "w") as f:
f.write(driver.page_source)
return html_file_name
fname = selenium_run(orig_comicart_marv_dc_50plus_200perpage_sold)
date and time: Sep-27-2021-13-19-13
print(fname)
sold_listings.html
with open(fname) as fp:
doc = BeautifulSoup(fp, 'html.parser')
For the sold products page, the classes for the title, link, and price tags are a little different.
title_class = 'lvtitle' price_class = 'bold bidsold' link_class = 'vip'
obtain a session URL, and then remove cookies from the session to avoid website blocking
s = requests.session()
Place it all into one function which will scrape for current or sold listings based on the function arguments.
def scrape_titles_and_prices(url, document):
s.cookies.clear()
update_datetime()
if document:
using_local_doc=True
doc = document
title_class = 'lvtitle'
price_class = 'bold bidsold'
link_class = 'vip'
else:
print('processing a link: ', url)
using_local_doc = False
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
filename = 'comic_art_marvel_dc' + today + '.html'
if searching_sold:
sold_html_file = filename
with open(filename, 'w') as f:
f.write(page_contents)
title_class = 's-item__title'
price_class = 's-item__price'
link_class = 's-item__link'
title_tags = doc.find_all('h3', {'class': title_class})
title_list = []
price_list = []
link_list = []
for i in range(len(title_tags)):
if (title_tags[i].contents):
if using_local_doc:
title_contents = title_tags[i].contents[0].contents[0]
else:
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if price.contents:
if len(price.contents)>1 and using_local_doc:
price_string = price.contents[1].contents[0]
else:
price_string = price.contents[0]
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
price_num = float(price_string)
price_list.append(price_num)
item_page_link = title_tags[i].findPrevious('a', href=True) # {'class': 's-item__link'})
if item_page_link.text:
href_text = item_page_link['href']
link_list.append(item_page_link['href'])
title_and_price_dict = {
'title': title_list,
'price': price_list,
'link': link_list
}
title_price_link_df = pd.DataFrame(title_and_price_dict)
# returns a data frame
return title_price_link_df
result = scrape_titles_and_prices("", doc)
date and time: Jul-17-2021-15-18-43
print(result[:10])
Empty DataFrame Columns: [title, price, link] Index: []
Exporting the Result to a .csv File
You might get an issue using.to csv in future tests after starting this project, therefore You will have to reduce the version of pandas to get this to work.
!pip uninstall pandas !pip install pandas==1.1.5 Found existing installation: pandas 1.3.3 Uninstalling pandas-1.3.3: Would remove: /usr/local/lib/python3.7/dist-packages/pandas-1.3.3.dist-info/* /usr/local/lib/python3.7/dist-packages/pandas/* Proceed (y/n)? y Successfully uninstalled pandas-1.3.3 Collecting pandas==1.1.5 Downloading pandas-1.1.5-cp37-cp37m-manylinux1_x86_64.whl (9.5 MB) |████████████████████████████████| 9.5 MB 7.3 MB/s Requirement already satisfied: numpy>=1.15.4 in /usr/local/lib/python3.7/dist-packages (from pandas==1.1.5) (1.19.5) Requirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas==1.1.5) (2.8.2) Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas==1.1.5) (2018.9) Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas==1.1.5) (1.15.0) Installing collected packages: pandas ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. google-colab 1.0.0 requires requests~=2.23.0, but you have requests 2.26.0 which is incompatible. Successfully installed pandas-1.1.5 update_datetime() fname = "origcomicart" + "-sold-" + today + ".csv" result.to_csv(fname, index=None) print(fname) date and time: Sep-27-2021-13-25-01 origcomicart-sold-Sep-27-2021-13-25-01.csv
Cycle Through all the Links in the CSV File
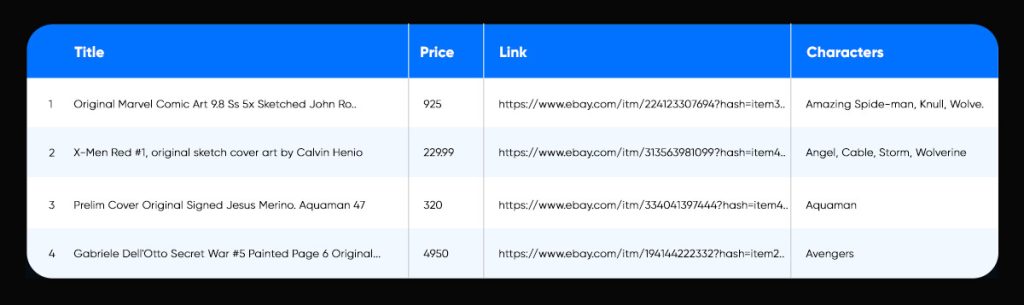
Go into each link and visit the individual listing page to collect the identity of the character, as well as all characters on the art, now that we have a.csv file with all the sold listings (the same goes for a csv file with all the current listings).
import csv
def indiv_page_link_cycler(csv_name):
with open(csv_name, newline='') as f:
reader = csv.reader(f)
data = list(reader)
# go through each link and add character to each list
# skip header row
for i in range(1, len(data)):
if(i%50==0):
update_datetime()
print(i,' :links processed')
link = data[i][2]
response = requests.get(link)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
searched_word = 'Character'
selection_class = 'attrLabels'
character_tags = doc.find_all('td', {'class': selection_class})
for j in range(len(character_tags)):
if (character_tags[j].contents):
fullstring = character_tags[j].contents[0]
if ("Character" or "character") in fullstring:
character = character_tags[j].findNext('span')
data[i].append(character.text)
data[0].append('characters')
data[0].append('multi-characters')
fname = csv_name[:-4]
fname = fname + "_chars.csv"
with open(fname, 'w') as file:
writer = csv.writer(file)
writer.writerows(data)
Copy and paste the csv format files name from the previous output
indiv_page_link_cycler(fname) date and time: Sep-27-2021-13-26-48 50 :links processed date and time: Sep-27-2021-13-27-27 100 :links processed date and time: Sep-27-2021-13-28-08 150 :links processed date and time: Sep-27-2021-13-28-47 200 :links processed
Each entry is added with the identities of the characters in a new csv file. The file is identical to the one above, with the addition of “_chars” at the end.
!pip install requests --upgrade --quiet !pip install bs4 --upgrade --quiet !pip install pandas --upgrade --quiet !pip install datetime --upgrade --quiet !pip install selenium --upgrade --quiet !pip install selenium_stealth --upgrade --quiet !apt update !apt install chromium-chromedriver
Get:1 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB] Get:2 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran40/ InRelease [3,626 B] Ign:3 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease Get:4 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic InRelease [15.9 kB] Ign:5 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease Hit:6 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release Hit:7 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release Hit:8 http://archive.ubuntu.com/ubuntu bionic InRelease Get:9 http://archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB] Hit:10 http://ppa.launchpad.net/cran/libgit2/ubuntu bionic InRelease Get:11 http://security.ubuntu.com/ubuntu bionic-security/main amd64 Packages [2,221 kB] Hit:12 http://ppa.launchpad.net/deadsnakes/ppa/ubuntu bionic InRelease Get:13 http://archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB] Hit:14 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease Get:15 http://security.ubuntu.com/ubuntu bionic-security/universe amd64 Packages [1,418 kB] Get:18 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic/main Sources [1,780 kB] Get:19 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 Packages [2,658 kB] Get:20 http://ppa.launchpad.net/c2d4u.team/c2d4u4.0+/ubuntu bionic/main amd64 Packages [911 kB] Get:21 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages [2,188 kB] Fetched 11.4 MB in 3s (3,327 kB/s) Reading package lists... Done Building dependency tree Reading state information... Done 41 packages can be upgraded. Run 'apt list --upgradable' to see them. Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: chromium-browser chromium-browser-l10n chromium-codecs-ffmpeg-extra Suggested packages: webaccounts-chromium-extension unity-chromium-extension The following NEW packages will be installed: chromium-browser chromium-browser-l10n chromium-chromedriver chromium-codecs-ffmpeg-extra 0 upgraded, 4 newly installed, 0 to remove and 41 not upgraded. Need to get 86.0 MB of archives. After this operation, 298 MB of additional disk space will be used. Get:1 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-codecs-ffmpeg-extra amd64 91.0.4472.101-0ubuntu0.18.04.1 [1,124 kB] Get:2 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-browser amd64 91.0.4472.101-0ubuntu0.18.04.1 [76.1 MB] Get:3 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-browser-l10n all 91.0.4472.101-0ubuntu0.18.04.1 [3,937 kB] Get:4 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 chromium-chromedriver amd64 91.0.4472.101-0ubuntu0.18.04.1 [4,837 kB] Fetched 86.0 MB in 4s (19.2 MB/s) Selecting previously unselected package chromium-codecs-ffmpeg-extra. (Reading database ... 160837 files and directories currently installed.) Preparing to unpack .../chromium-codecs-ffmpeg-extra_91.0.4472.101-0ubuntu0.18.04.1_amd64.deb ... Unpacking chromium-codecs-ffmpeg-extra (91.0.4472.101-0ubuntu0.18.04.1) ... Selecting previously unselected package chromium-browser. Preparing to unpack .../chromium-browser_91.0.4472.101-0ubuntu0.18.04.1_amd64.deb ... Unpacking chromium-browser (91.0.4472.101-0ubuntu0.18.04.1) ... Selecting previously unselected package chromium-browser-l10n. Preparing to unpack .../chromium-browser-l10n_91.0.4472.101-0ubuntu0.18.04.1_all.deb ... Unpacking chromium-browser-l10n (91.0.4472.101-0ubuntu0.18.04.1) ... Selecting previously unselected package chromium-chromedriver. Preparing to unpack .../chromium-chromedriver_91.0.4472.101-0ubuntu0.18.04.1_amd64.deb ... Unpacking chromium-chromedriver (91.0.4472.101-0ubuntu0.18.04.1) ... Setting up chromium-codecs-ffmpeg-extra (91.0.4472.101-0ubuntu0.18.04.1) ... Setting up chromium-browser (91.0.4472.101-0ubuntu0.18.04.1) ... update-alternatives: using /usr/bin/chromium-browser to provide /usr/bin/x-www-browser (x-www-browser) in auto mode update-alternatives: using /usr/bin/chromium-browser to provide /usr/bin/gnome-www-browser (gnome-www-browser) in auto mode Setting up chromium-chromedriver (91.0.4472.101-0ubuntu0.18.04.1) ... Setting up chromium-browser-l10n (91.0.4472.101-0ubuntu0.18.04.1) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... Processing triggers for hicolor-icon-theme (0.17-2) ... Processing triggers for mime-support (3.60ubuntu1) ... Processing triggers for libc-bin (2.27-3ubuntu1.2) ... /sbin/ldconfig.real: /usr/local/lib/python3.7/dist-packages/ideep4py/lib/libmkldnn.so.0 is not a symbolic link
from __future__ import division, unicode_literals
import requests
from bs4 import BeautifulSoup
from re import sub
from decimal import Decimal
import pandas as pd
import requests
import random
import time
import os
import csv
from datetime import date
from datetime import datetime
import codecs
from selenium import webdriver
from selenium_stealth import stealth
import time
import random
s = requests.session()
s.cookies.clear()
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
def update_datetime():
global now
global today
global date_time
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
print("date and time:", today)
html_doc = """
<html><head><title>place holder</title></head>
"""
s.cookies.clear()
# this just initializes the beautiful soup doc as a global variable
doc = BeautifulSoup(html_doc, 'html.parser')
def scrape_titles_and_prices(url, document):
s.cookies.clear()
update_datetime()
if document:
using_local_doc=True
doc = document
title_class = 'lvtitle'
price_class = 'bold bidsold'
link_class = 'vip'
else:
print('processing a link: ', url)
using_local_doc = False
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
filename = 'comic_art_marvel_dc' + today + '.html'
if searching_sold:
sold_html_file = filename
with open(filename, 'w') as f:
f.write(page_contents)
title_class = 's-item__title'
price_class = 's-item__price'
link_class = 's-item__link'
title_tags = doc.find_all('h3', {'class': title_class})
title_list = []
price_list = []
link_list = []
for i in range(len(title_tags)):
if (title_tags[i].contents):
if using_local_doc:
title_contents = title_tags[i].contents[0].contents[0]
else:
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if price.contents:
if len(price.contents)>1 and using_local_doc:
price_string = price.contents[1].contents[0]
else:
price_string = price.contents[0]
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
price_num = float(price_string)
price_list.append(price_num)
item_page_link = title_tags[i].findPrevious('a', href=True) # {'class': 's-item__link'})
if item_page_link.text:
href_text = item_page_link['href']
link_list.append(item_page_link['href'])
title_and_price_dict = {
'title': title_list,
'price': price_list,
'link': link_list
}
title_price_link_df = pd.DataFrame(title_and_price_dict)
return title_price_link_df
def build_pagelink_list(url):
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
for a in doc.find_all('a', href=True):
if a.text:
href_text = a['href']
if (href_text.find('pgn=') != -1):
links_with_pgn_text.append(a['href'])
if (len(links_with_pgn_text) < 1):
links_with_pgn_text.append(url)
def scrape_all_pages():
time.sleep(random.randint(1, 4))
for i in range(0, len(links_with_pgn_text)):
next_page_url = links_with_pgn_text[i]
frames.append(scrape_titles_and_prices(next_page_url,""))
time.sleep(random.randint(1, 2))
# main program
def main_scraping(url):
build_pagelink_list(url)
scrape_all_pages()
if (len(frames) > 1):
result = pd.concat(frames, ignore_index=True)
else:
result = frames
result.sort_values(by=['price'])
update_datetime()
fname = "origcomicart" + "_" + today + ".csv"
result.to_csv(fname, index=None)
return fname
def parse_local_file(fname):
with open(fname) as fp:
document = BeautifulSoup(fp, 'html.parser')
frames.append(scrape_titles_and_prices("", document))
if (len(frames) > 1):
result = pd.concat(frames, ignore_index=True)
else:
result = frames[0]
result.sort_values(by=['price'])
update_datetime()
fname = "origcomicart" + "_" + today + ".csv"
result.to_csv(fname, index=None)
return fname
def indiv_page_link_cycler(csv_name):
with open(csv_name, newline='') as f:
reader = csv.reader(f)
data = list(reader)
for i in range(1, len(data)):
if(i%50==0):
update_datetime()
print(i,' :links processed')
link = data[i][2]
response = requests.get(link)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
searched_word = 'Character'
selection_class = 'attrLabels'
character_tags = doc.find_all('td', {'class': selection_class})
for j in range(len(character_tags)):
if (character_tags[j].contents):
fullstring = character_tags[j].contents[0]
if ("Character" or "character") in fullstring:
character = character_tags[j].findNext('span')
data[i].append(character.text)
data[0].append('characters')
data[0].append('multi-characters')
fname = csv_name[:-4]
fname = fname + "_chars.csv"
with open(fname, 'w') as file:
writer = csv.writer(file)
writer.writerows(data)
def add_headers(csv_file):
with open(csv_file, newline='') as f:
reader = csv.reader(f)
data = list(reader)
data[0].append('characters')
data[0].append('multi-characters')
fname = csv_file[:-4]
fname = fname + "_append.csv"
with open(fname, 'w') as file:
writer = csv.writer(file)
writer.writerows(data)
def selenium_run(url):
# open it, go to a website, and get results
driver = webdriver.Chrome('chromedriver',options=options)
# set selenium options to be headless, ..
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
#wd.get("https://www.ebay.com/sch/i.html?_fsrp=1&_from=R40&_sacat=0&LH_Sold=1&_mPrRngCbx=1&_udlo=50&_udhi&LH_BIN=1&_samilow&_samihi&_sadis=15&_stpos=10002&_sop=16&_dmd=1&_ipg=200&_fosrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&LH_Complete=1&_nkw=original%20comic%20art&_dcat=3984&rt=nc&Publisher=DC%2520Comics%7CMarvel%7CMarvel%2520Comics")
#print(wd.page_source) # results
#PATH = '/Users/jmartin/Downloads/chromedriver'
#options = webdriver.ChromeOptions()
#options.add_argument("start-maximized")
#options.add_argument("--headless")
#options.add_experimental_option("excludeSwitches", ["enable-automation"])
#options.add_experimental_option('useAutomationExtension', False)
#driver = webdriver.Chrome(options=options, executable_path=r"/Users/jmartin/Downloads/chromedriver")
stealth(
driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.53 Safari/537.36',
languages = "en",
vendor = "Google Inc.",
platform = "Win32",
webgl_vendor = "Intel Inc.",
renderer = "Intel Iris OpenGL Engine",
fix_hairline = False,
run_on_insecure_origins = False
)
driver.delete_all_cookies()
driver.get(url)
update_datetime()
#html_file_name = "sold_page_source-" + today + ".html"
html_file_name = "sold_listings.html"
with open(html_file_name, "w") as f:
f.write(driver.page_source)
return html_file_name
orig_comicart_marv_dc_50plus_200perpage = 'https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200'
orig_comicart_marv_dc_50plus_200perpage_sold = 'https://www.ebay.com/sch/i.html?_fsrp=1&_from=R40&_sacat=0&LH_Sold=1&_mPrRngCbx=1&_udlo=50&_udhi&LH_BIN=1&_samilow&_samihi&_sadis=15&_stpos=10002&_sop=16&_dmd=1&_ipg=200&_fosrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&LH_Complete=1&_nkw=original%20comic%20art&_dcat=3984&rt=nc&Publisher=DC%2520Comics%7CMarvel%7CMarvel%2520Comics'
# run the main scraping function
searching_sold = False
links_with_pgn_text = []
data = []
frames = []
#search for current orig comic listings
search_url = orig_comicart_marv_dc_50plus_200perpage
current_sales_csv = main_scraping(search_url)
indiv_page_link_cycler(current_sales_csv)
# now try to save the html for the sold data
# usually it blocks the sales data
links_with_pgn_text.clear()
data.clear()
frames.clear()
sold_html_file = ""
searching_sold = True
search_url = orig_comicart_marv_dc_50plus_200perpage_sold
#seach listing for sold items
#below can also be run locally with selenium after you install the webdriver
#and change the PATH variable so it points to your local installation directory
sold_html_file = selenium_run(orig_comicart_marv_dc_50plus_200perpage_sold)
#sold_html_file = "sold_listings.html"
update_datetime()
print("now parsing sold items")
past_sales_csv = parse_local_file(sold_html_file)
indiv_page_link_cycler(past_sales_csv)
date and time: Jul-08-2021-13-50-40 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=1 date and time: Jul-08-2021-13-50-42 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=2 date and time: Jul-08-2021-13-50-45 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=3 date and time: Jul-08-2021-13-50-47 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=4 date and time: Jul-08-2021-13-50-51 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=5&rt=nc date and time: Jul-08-2021-13-50-57 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=6&rt=nc date and time: Jul-08-2021-13-51-01 date and time: Jul-08-2021-13-51-33 50 :links processed date and time: Jul-08-2021-13-52-06 100 :links processed date and time: Jul-08-2021-13-52-39 150 :links processed date and time: Jul-08-2021-13-53-12 200 :links processed date and time: Jul-08-2021-13-53-44 250 :links processed date and time: Jul-08-2021-13-54-17 300 :links processed date and time: Jul-08-2021-13-54-51 350 :links processed date and time: Jul-08-2021-13-55-23 400 :links processed date and time: Jul-08-2021-13-55-56 450 :links processed date and time: Jul-08-2021-13-56-26 500 :links processed date and time: Jul-08-2021-13-56-58 550 :links processed date and time: Jul-08-2021-13-57-29 600 :links processed date and time: Jul-08-2021-13-58-02 650 :links processed date and time: Jul-08-2021-13-58-34 700 :links processed date and time: Jul-08-2021-13-59-06 750 :links processed date and time: Jul-08-2021-13-59-36 800 :links processed date and time: Jul-08-2021-13-59-42 now parsing sold items date and time: Jul-08-2021-13-59-42 date and time: Jul-08-2021-13-59-42 date and time: Jul-08-2021-14-00-19 50 :links processed date and time: Jul-08-2021-14-00-57 100 :links processed
Final Code
from __future__ import division, unicode_literals
import requests
from bs4 import BeautifulSoup
from re import sub
from decimal import Decimal
import pandas as pd
import requests
import random
import time
import os
import csv
from datetime import date
from datetime import datetime
import codecs
from selenium import webdriver
from selenium_stealth import stealth
import time
import random
s = requests.session()
s.cookies.clear()
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
def update_datetime():
global now
global today
global date_time
now = datetime.now()
today = date.today()
today = today.strftime("%b-%d-%Y")
date_time = now.strftime("%H-%M-%S")
today = today + "-" + date_time
print("date and time:", today)
html_doc = """
<html><head><title>place holder</title></head>
"""
s.cookies.clear()
# this just initializes the beautiful soup doc as a global variable
doc = BeautifulSoup(html_doc, 'html.parser')
def scrape_titles_and_prices(url, document):
s.cookies.clear()
update_datetime()
if document:
using_local_doc=True
doc = document
title_class = 'lvtitle'
price_class = 'bold bidsold'
link_class = 'vip'
else:
print('processing a link: ', url)
using_local_doc = False
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
filename = 'comic_art_marvel_dc' + today + '.html'
if searching_sold:
sold_html_file = filename
with open(filename, 'w') as f:
f.write(page_contents)
title_class = 's-item__title'
price_class = 's-item__price'
link_class = 's-item__link'
title_tags = doc.find_all('h3', {'class': title_class})
title_list = []
price_list = []
link_list = []
for i in range(len(title_tags)):
if (title_tags[i].contents):
if using_local_doc:
title_contents = title_tags[i].contents[0].contents[0]
else:
title_contents = title_tags[i].contents[0]
title_list.append(title_contents)
price = title_tags[i].findNext('span', {'class': price_class})
if price.contents:
if len(price.contents)>1 and using_local_doc:
price_string = price.contents[1].contents[0]
else:
price_string = price.contents[0]
if (isinstance(price_string, str)):
price_string = sub(r'[^\d.]', '', price_string)
else:
price_string = price.contents[0].contents[0]
price_string = sub(r'[^\d.]', '', price_string)
price_num = float(price_string)
price_list.append(price_num)
item_page_link = title_tags[i].findPrevious('a', href=True) # {'class': 's-item__link'})
if item_page_link.text:
href_text = item_page_link['href']
link_list.append(item_page_link['href'])
title_and_price_dict = {
'title': title_list,
'price': price_list,
'link': link_list
}
title_price_link_df = pd.DataFrame(title_and_price_dict)
return title_price_link_df
def build_pagelink_list(url):
response = requests.get(url)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
for a in doc.find_all('a', href=True):
if a.text:
href_text = a['href']
if (href_text.find('pgn=') != -1):
links_with_pgn_text.append(a['href'])
if (len(links_with_pgn_text) < 1):
links_with_pgn_text.append(url)
def scrape_all_pages():
time.sleep(random.randint(1, 4))
for i in range(0, len(links_with_pgn_text)):
next_page_url = links_with_pgn_text[i]
frames.append(scrape_titles_and_prices(next_page_url,""))
time.sleep(random.randint(1, 2))
# main program
def main_scraping(url):
build_pagelink_list(url)
scrape_all_pages()
if (len(frames) > 1):
result = pd.concat(frames, ignore_index=True)
else:
result = frames
result.sort_values(by=['price'])
update_datetime()
fname = "origcomicart" + "_" + today + ".csv"
result.to_csv(fname, index=None)
return fname
def parse_local_file(fname):
with open(fname) as fp:
document = BeautifulSoup(fp, 'html.parser')
frames.append(scrape_titles_and_prices("", document))
if (len(frames) > 1):
result = pd.concat(frames, ignore_index=True)
else:
result = frames[0]
result.sort_values(by=['price'])
update_datetime()
fname = "origcomicart" + "_" + today + ".csv"
result.to_csv(fname, index=None)
return fname
def indiv_page_link_cycler(csv_name):
with open(csv_name, newline='') as f:
reader = csv.reader(f)
data = list(reader)
for i in range(1, len(data)):
if(i%50==0):
update_datetime()
print(i,' :links processed')
link = data[i][2]
response = requests.get(link)
if (response.status_code != 200):
raise Exception('Failed to load page {}'.format(url))
page_contents = response.text
doc = BeautifulSoup(page_contents, 'html.parser')
searched_word = 'Character'
selection_class = 'attrLabels'
character_tags = doc.find_all('td', {'class': selection_class})
for j in range(len(character_tags)):
if (character_tags[j].contents):
fullstring = character_tags[j].contents[0]
if ("Character" or "character") in fullstring:
character = character_tags[j].findNext('span')
data[i].append(character.text)
data[0].append('characters')
data[0].append('multi-characters')
fname = csv_name[:-4]
fname = fname + "_chars.csv"
with open(fname, 'w') as file:
writer = csv.writer(file)
writer.writerows(data)
def add_headers(csv_file):
with open(csv_file, newline='') as f:
reader = csv.reader(f)
data = list(reader)
data[0].append('characters')
data[0].append('multi-characters')
fname = csv_file[:-4]
fname = fname + "_append.csv"
with open(fname, 'w') as file:
writer = csv.writer(file)
writer.writerows(data)
def selenium_run(url):
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
# open it, go to a website, and get results
driver = webdriver.Chrome('chromedriver',options=options)
# uncomment below and change paths if running locally (and comment the line above)
#PATH = '/Users/jmartin/Downloads/chromedriver'
#driver = webdriver.Chrome(options=options, executable_path=r"/Users/jmartin/Downloads/chromedriver")
stealth(
driver,
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.53 Safari/537.36',
languages = "en",
vendor = "Google Inc.",
platform = "Win32",
webgl_vendor = "Intel Inc.",
renderer = "Intel Iris OpenGL Engine",
fix_hairline = False,
run_on_insecure_origins = False
)
driver.delete_all_cookies()
driver.get(url)
update_datetime()
#html_file_name = "sold_page_source-" + today + ".html"
html_file_name = "sold_listings.html"
with open(html_file_name, "w") as f:
f.write(driver.page_source)
return html_file_name
orig_comicart_marv_dc_50plus_200perpage = 'https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200'
orig_comicart_marv_dc_50plus_200perpage_sold = 'https://www.ebay.com/sch/i.html?_fsrp=1&_from=R40&_sacat=0&LH_Sold=1&_mPrRngCbx=1&_udlo=50&_udhi&LH_BIN=1&_samilow&_samihi&_sadis=15&_stpos=10002&_sop=16&_dmd=1&_ipg=200&_fosrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&LH_Complete=1&_nkw=original%20comic%20art&_dcat=3984&rt=nc&Publisher=DC%2520Comics%7CMarvel%7CMarvel%2520Comics'
# run the main scraping function
searching_sold = False
links_with_pgn_text = []
data = []
frames = []
#search for current orig comic listings
search_url = orig_comicart_marv_dc_50plus_200perpage
current_sales_csv = main_scraping(search_url)
indiv_page_link_cycler(current_sales_csv)
# now try to save the html for the sold data
# usually it blocks the sales data
links_with_pgn_text.clear()
data.clear()
frames.clear()
sold_html_file = ""
searching_sold = True
search_url = orig_comicart_marv_dc_50plus_200perpage_sold
#seach listing for sold items
#below can also be run locally with selenium after you install the webdriver
#and change the PATH variable so it points to your local installation directory
sold_html_file = selenium_run(orig_comicart_marv_dc_50plus_200perpage_sold)
#sold_html_file = "sold_listings.html"
update_datetime()
print("now parsing sold items")
past_sales_csv = parse_local_file(sold_html_file)
indiv_page_link_cycler(past_sales_csv)
date and time: Sep-27-2021-14-02-53 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=1 date and time: Sep-27-2021-14-02-55 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=2 date and time: Sep-27-2021-14-02-59 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=3 date and time: Sep-27-2021-14-03-02 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=4 date and time: Sep-27-2021-14-03-05 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=5&rt=nc date and time: Sep-27-2021-14-03-10 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=6&rt=nc date and time: Sep-27-2021-14-03-15 processing a link: https://www.ebay.com/sch/i.html?_dcat=3984&_fsrp=1&Type=Cover%7CInterior%2520Page%7CSplash%2520Page&_from=R40&_nkw=original+comic+art&_sacat=0&Publisher=Marvel%2520Comics%7CDC%2520Comics%7CUltimate%2520Marvel%7CMarvel%2520Age%7CMarvel%2520Adventures%7CMarvel&LH_BIN=1&_udlo=50&_sop=16&_ipg=200&_pgn=7&rt=nc date and time: Sep-27-2021-14-03-19 date and time: Sep-27-2021-14-03-51 50 :links processed date and time: Sep-27-2021-14-04-23 100 :links processed date and time: Sep-27-2021-14-04-55 150 :links processed date and time: Sep-27-2021-14-05-28 200 :links processed date and time: Sep-27-2021-14-06-02 250 :links processed date and time: Sep-27-2021-14-06-35 300 :links processed date and time: Sep-27-2021-14-07-07 350 :links processed date and time: Sep-27-2021-14-07-40 400 :links processed date and time: Sep-27-2021-14-08-14 450 :links processed date and time: Sep-27-2021-14-08-46 500 :links processed date and time: Sep-27-2021-14-09-20 550 :links processed date and time: Sep-27-2021-14-09-52 600 :links processed date and time: Sep-27-2021-14-10-25 650 :links processed date and time: Sep-27-2021-14-10-56 700 :links processed date and time: Sep-27-2021-14-11-30 750 :links processed date and time: Sep-27-2021-14-12-03 800 :links processed date and time: Sep-27-2021-14-12-11 date and time: Sep-27-2021-14-12-11 now parsing sold items date and time: Sep-27-2021-14-12-11 date and time: Sep-27-2021-14-12-11
Summary
- Our purpose for this research was to obtain two csv files relating to original comic art on eBay.
- The first csv file featured all of Marvel and DC’s current lists of inside pages, covers, and splash pages.
- The second csv file had similar data about things that had been sold.
- This allowed us to swiftly (far faster than eBay’s UI) search the current offerings for paintings in a specific price range and characters that looked interesting. We may then seek for comparable art in the csv of sold things to evaluate if this was a decent buy.
The Steps that We Used
- To access the html content from a URL generated by eBay’s filtering system, use the requests library.
- Use BeautifulSoup to look for tags (p, div, a, etc.) in the html text of the original search page results for the data we needed, such as: listing title and description, link to full listing, and price
- Include this information in your listings.
- Make a pandas data frame out of the lists and save it as a csv file.
- Then browse through the links and open each full artwork listing with requests, then utilize BeautifulSoup to get the character details.
- Create a csv file with the data frame.
- Because eBay prohibited the use of requests to obtain this html content for sold items, we had to store the html content as an html file using Selenium. We then opened this file in BeautifulSoup and parsed it using the same methods.
For more details, contact 3i Data Scraping today
Request for a quote!!













What Will We Do Next?
- Our representative will contact you within 24 hours.
- We will collect all the necessary requirements from you.
- The team of analysts and developers will prepare estimation.
- We keep confidentiality with all our clients by signing NDA.



